Barranco
A real-time coordination tool for canyoning clubs. Features nearby canyon discovery, trip scheduling, group chat, live weather and water-level aggregation, and automated shuttle planning. All for free. :)
demo.barranco.app ↗
Canyoning clubs organize treffens: multi-day gatherings at a base location (e.g. a camping) with daily trips to different canyons. Problem: coordination usually happens through WhatsApp groups or in-person. Which works, but info ends up scattered and in people's heads. Additionally, there's important info such as weather and water levels that you need to be aware of, and that usually entails consulting various models and aggregating the info yourself. I wanted one tool that did all that automatically.
The backend runs on Phoenix coupled with Ash Framework, which is a declarative framework where you define a resource once and it derives migrations, queries, authorization, and a typed API from that single definition. This was also the first thing I built leaning heavily on Claude Code, and the declarative style is a big part of why that worked (I think). The idea is: you describe a resource once and Ash derives the rest. So there's less code for Claude to write and less for it to get wrong. It's typed end to end too, so the mistakes it does make tend to break the build instead of slipping through. In other words, an AI agent gets immediate and actionable feedback, so it can keep iterating on its own.
The frontend runs on React. Not much to say about that. :) Backend updates are pushed to the frontend over Phoenix Channels, a messaging abstraction that sits on top of WebSockets (usually).
The one real decision was React vs LiveView. LiveView is the Elixir-native option and would've collapsed a lot of this: no React, no typed RPC, no separate channel types. I went with React anyway, because I wanted the richer frontend (the maps, the animations, the component library). The typed RPC and typed channels already make it a lot easier to work with.
Architecture
Tech stack
Backend
Frontend
Infrastructure
Overview
Ash Framework: "model your domain, derive the rest"
Ash is a declarative framework for Elixir. You define a resource once: its attributes, actions, relationships, and authorization policies. From that single declaration, Ash derives database migrations, query interfaces, and validation logic. On top of that,AshTypescriptgenerates a fully typed TypeScript RPC client, so the React frontend calls generated functions that map 1:1 to Ash actions.
Authorization is policy-based and declared on the resource too. For example, only trip participants can claim equipment, and only club admins can approve join requests. These rules live next to the data model, not scattered across controllers.
Real-time updates
When someone joins a trip, claims equipment, or posts a comment, every connected client sees the change immediately.
Real-time fan-out is declarative on both ends. Each Ash resource carries a pub_sub block that declares which actions broadcast, to which topics, and with what optional filters or transforms, and Ash does the broadcasting. On the channel side,AshTypescript.TypedChannel generates typed channel definitions from those rules, so the React frontend gets compile-time type checking on every event name and payload shape. Rename an event or change a payload shape and the build breaks.
On the frontend, TanStack Query listens for typed channel events and selectively invalidates only the affected queries, so the UI refetches just what changed.

Multi-model weather forecasting
Weather is unreliable from a single source, especially in the mountains. Barranco fetches forecasts from 6 different weather models viaOpen-Meteo. All 6 models are fetched in parallel and cached for a certain duration. The UI displays all models so canyoneers can compare predictions and make informed decisions.
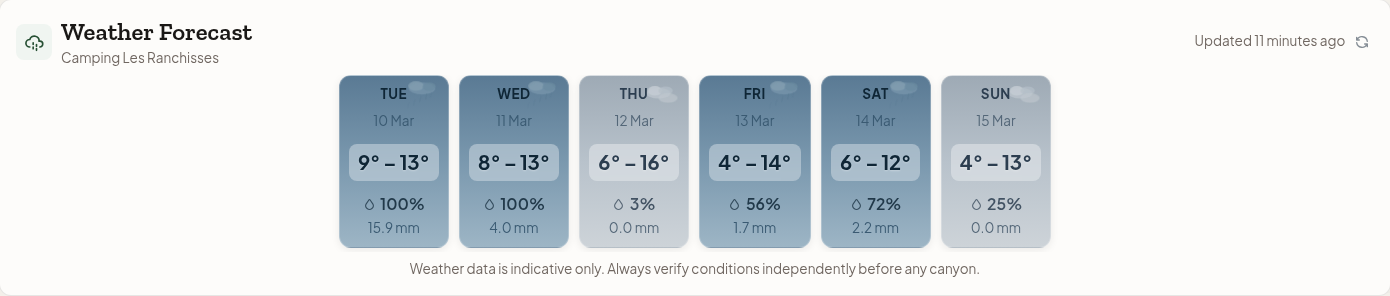
Water levels
Water is often the deciding factor for determining whether a canyon is safe to descend. Barranco fetches gauge readings from French and Swiss water authorities in parallel and finds the nearest stations. In future, I'd prefer to only show stations of rivers that run through the canyon, since that might absolutely not be the case if you're only going off on distance.
Canyon database
I pull canyon data from OpenCanyon, an open database maintained by the Austrian Canyoning Association, with around 6,800 canyons across 41 countries (CC BY-NC-SA 4.0). A bulk import grabs the full GeoJSON dataset: coordinates, difficulty ratings, and waypoints for parking and the canyon start and end points. A separate enrichment worker then visits individual canyon pages for the specs that aren't in the API: number of rappels, max rope length, total descent, whether a shuttle is needed, and a photo for the thumbnail.
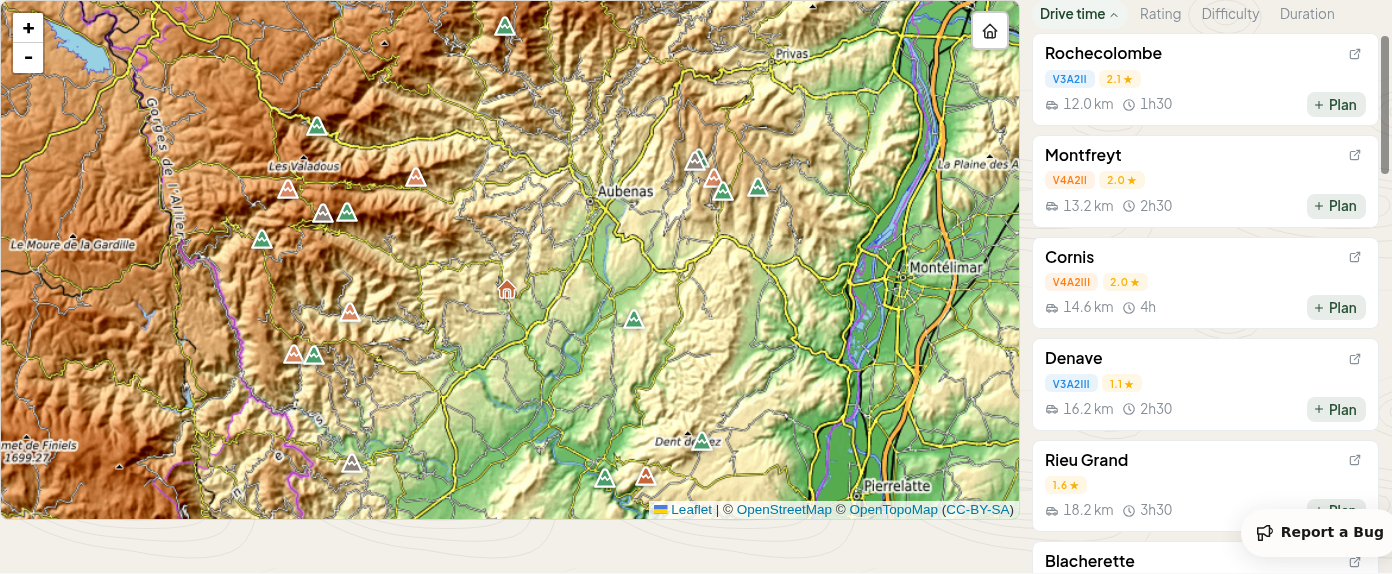
Shuttle planning
Most canyons start and end at different points. The usual approach: drive all cars to the exit, leave dry clothes, then get into as few cars as possible and drive to the entry. After the descent, the shuttle drivers go back to the entry and pick up cars that were left there.
The algorithm picks shuttle cars greedily: sort drivers by capacity, select the biggest cars until there are enough seats, and leave the rest at the exit for retrieval. If one shuttle run isn't enough, it calculates multiple passes.
It's a small bin packing problem, and a greedy solution doesn't cover every edge case perfectly, but groups are small enough that it works well in practice. And it's simple, which is an advantage on its own.
Landing page
I wanted something bold and cinematic, given the somewhat extreme nature of canyoning. There's not a lot of source material, though. Most canyoning vids are low-quality, taken with a GoPro or something similar. There's a couple of really-high end movies on YouTube by brave souls that took their DSLR into the canyon, which I maybe could have used, but seeing as Replit Animations coincidentally launched at the same time, I ended up giving that a go. It's prompt-driven 'motion graphics' generation, as they put it. Initially I envisioned a person rappelling down the rope with the camera wall-facing, but the model was having a lot of trouble generating realistic rope movement. Ended up cutting the human out of the animations and just going with a movie in nature. The result is a beautiful (and entirely artificial) movie of a river flowing through a canyon.
Deployment
Kamal deploys Docker containers to a €3 Hetzner VPS with zero-downtime rolling deploys. CI runs on Buildkite with custom runners on a different Hetzner VPS.
I'm a freelance software engineer. If you've got something you want built,send me an email. I read and reply to every one.